Table of Contents
Discontinued Approaches
Direct CNN Approach
This was the first attempted approach towards solving the audio/video synchronization problem. This was also the one highlighted in the initial proposal. The model consists of two CNNs, a concatenation step to join the branches, several fully-connected layers, and a linear output neuron that represents the frame offset between the audio and video inputs. The CNNs were trained simultaneously on video frame windows and spectrograms from their corresponding audio segments.
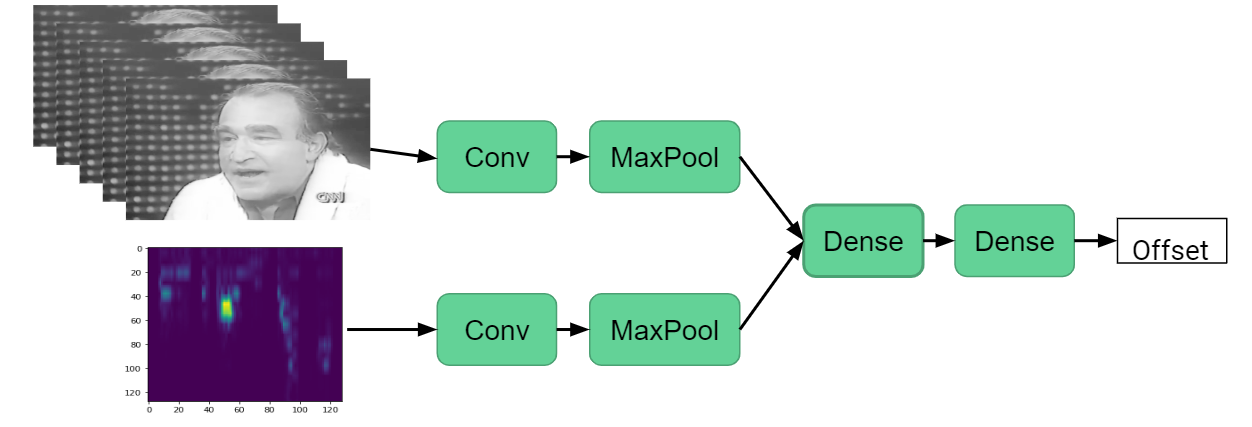
CNN Architecture
We did not pursue this approach because initially, the model was trained on grayscale faces, which filled the neural network with irrelevant information besides the mouth movement. Despite applying the following fixes, the model could not achieve an adequate fit:
- Cropping out the mouth
- Using the difference between frames instead of the frames themselves
- Increasing the window size
- Adding more convolutional and fully-connected layers
- Training on only one video
- Limiting the maximum offset
Therefore, it is likely that our initial architecture is not suitable for this problem.
This approach can be found under: Strategy 1 on Google Colab
SyncNet-Inspired Approach
The third attempted strategy was based on the SyncNet paper [7]. The authors were able to accomplish audio-video synchronization at an accuracy of 81% with a window size of only 5 frames. SyncNet consists of two similar DNNs that output size-256 vectors. The inputs are a five-frame window and the MFCC features of the corresponding audio segment. The L2 distance between the output vectors determines whether an audio and video pair is synchronized. SyncNet is trained on genuine (in-sync) and false (out-of-sync) pairs. To find the audio-video offset of a particular video, one must extract audio and video pairs from the video, feed them to SyncNet, average the L2 distances over a set time, and repeat by manually sliding the audio and/or the video stream. The offset that returns the least average L2 distance is most likely the correct one.
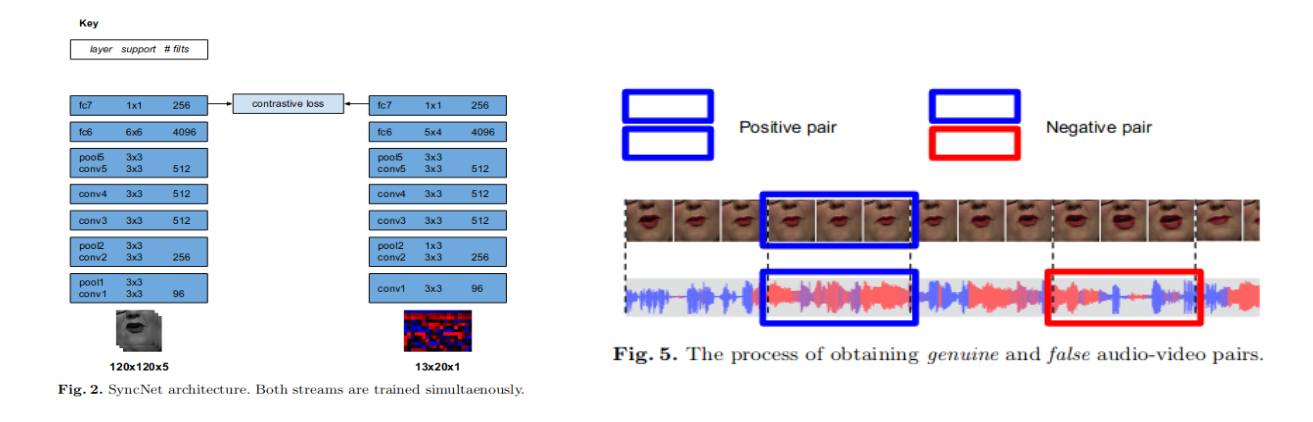
Source: https://www.robots.ox.ac.uk/~vgg/publications/2016/Chung16a/chung16a.pdf
This strategy was not pursued for the following reasons:
- We had inadequate resources. The GPU provided by Google Colab barely had enough memory for training audio and video pairs from one video. In contrast, the authors trained SyncNet on hundreds of hours of video using high-end hardware.
- Although the SyncNet architecture was implemented on Google Colab using the parameters described in the paper, the model overfit. Possible factors include not enough training data, an unforeseen bug in the pair generation code, and poor video quality.
This approach can be found under: Strategy 3 on Google Colab