Table of Contents
Methodology
Media Capturing
In order to capture what a user see and hear from a stream service, thereby encompassing all latency that could be introduced between the audio/video files, a recording device/software independent from the player of the streaming service must be introduced. For streaming services accessed on a computer or a laptop, the recording can be handled by a screen + audio recording software on the same device or by an external device such as a mobile phone or a video camera. We decided to work screen + audio recording software (e.g. Camtasia, OBS, ShareX, Python codes for screen recording, etc.) as this approach gives us an easier time to maintain the deployed codes, libraries, and packages. After comparing the performance of multiple screen + audio recording software, we selected FFmpeg due to its versatility across operating systems and the ability to have it controlled by some backend process. By incorporating FFmpeg into Python via subprocess calls, including virtual audio and screen capturers, and adding codes that allows use to select the region of screen for recording, we provide a piece of Python program that achieve good quality in screen + audio recording.
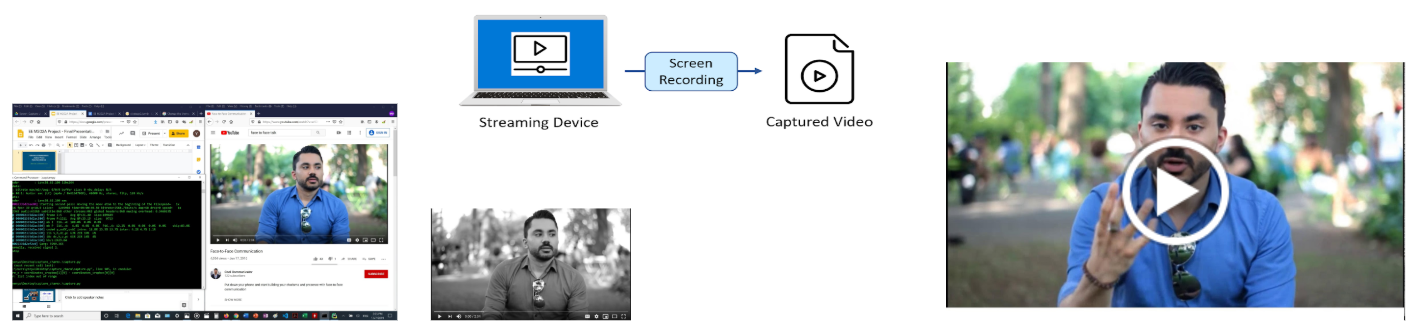
Media Capture Technique
It is possible to record only a portion of the targeted video streaming using the presented Python screen recording program. However, it is assumed that the entire video file is available for the selected audio and video synchronization approach presented in this project.
This approach can be found under: Media Capture Technique
Demultiplexing of Video and Audio Files
In order to properly run a neural network analysis and subsequent shifting of the video and audio stream files, the original video file must be demultiplexed. FFmpeg is a powerful tool which provides the capability to strip away the audio from a video file, while also allowing them to be spliced back together following the calculated time shift. Once these files have been isolated, they can be further processed. Through multiple stages of processing for each file, the relevant information can be separately extracted and processed. By extracting information from the audio stream and the video frames, the computational complexity is also drastically reduced.
Feature Processing
This project focuses on videos that portray a single full frontal speaker, in case where both the audio leads and lags the video. Initially, the plan was to only focus on cases where audio lags the video, but the selected approach proved to be robust. For the purposes of correcting this audio and video stream offset, two major feature extraction techniques were applied: mouth aspect ratio computation (MAR) and voice activity detection (VAD). The leading hypothesis was that the various start and end points of identified speech in the video could be correlated with the start and end points of speech in the audio. If there was some sort of offset between the two streams, a cross-correlation technique could be applied to find the optimal allignment, and hence the time offset.
Mouth Aspect Ratio
This calculation is broken up into two steps: the face detection and the MAR computation. The dlib Python module is first used to extract the detected face from each frame. This face is then matched to a shape landmark prediction file, where each coordinate in the file corresponds to a specific point on the face. The coordinates for the mouth are extracted from this file, and for each frame the MAR is computed based on the euclidian distances between the opposite horizontal landmarks and the euclidian distances between the opposite vertical landmarks of the mouth.
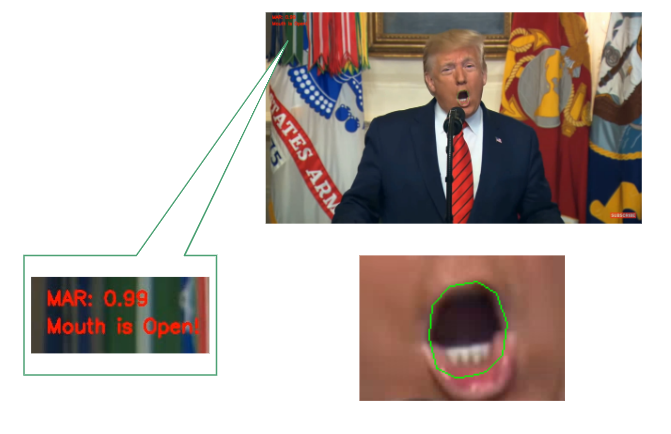
MAR Example
The output from the MAR function is a list of values corresponding to the aspect ratio of the mouth. Its size is equal to the total number of frames. The mouth aspect ratio implementation was inspired by the following: mouth-open on GitHub
Voice Activity Detection
Voice activity detectors are very common for speech processing, specifically when it comes to speech recognition in devices like Siri or Alexa. WebRTCVAD was the Python module used to take care of the voice activity detection, which was created for the Google WebRTC project and is supposedly one of the best VADs available. The selected VAD takes a 10ms section of audio at a time and assigns a binary 1 or 0 based on whether speech was detected during that period of time. It also takes an aggresiveness parameter argument of 0, 1, 2, or 3 which determines how strictly it classifies periods of sound as speech or silence. A higher VAD aggresiveness will generally result in less segments being classified as speech.
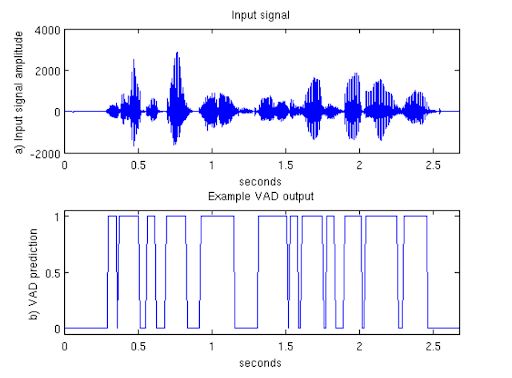
VAD Detection Example
Source: Voice Activity Detection (VAD) Tutorial
The extracted audio from the video file is fed through the VAD, and the output is a binary list corresponding to the sections of detected speech and silence. Following this, the data is resampled and smoothed to match the number of frames in the video file. The implementation was inspired by the following: py-webrtcvad on GitHub
Cross-Correlation
The voice activity detection and mouth aspect ration computation both provide two lists of the same size. A cross-correlation is run to determine the optimal allignment between these two vectors, and determine what time offset (if any) exists between them. The following two figures demonstrate an example of this process:
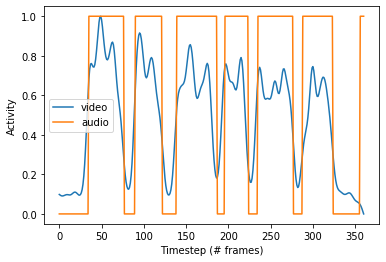
MAR and VAD Output for 0ms Offset Video
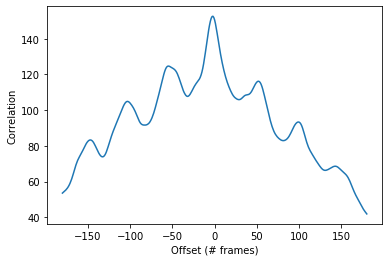
Cross-Correlation of Video and Audio Features for 0ms Offset Video
Time Offset Injection
Once the required time shift has been identified by the neural network output, the FFmpeg tool is used again to inject the lead or lag in the audio file. The delay-injected audio and original video files are then combined. The original video file is not modified in any way, and instead a new synchronized video file is created.
The following diagram summarizes the data pipeline:
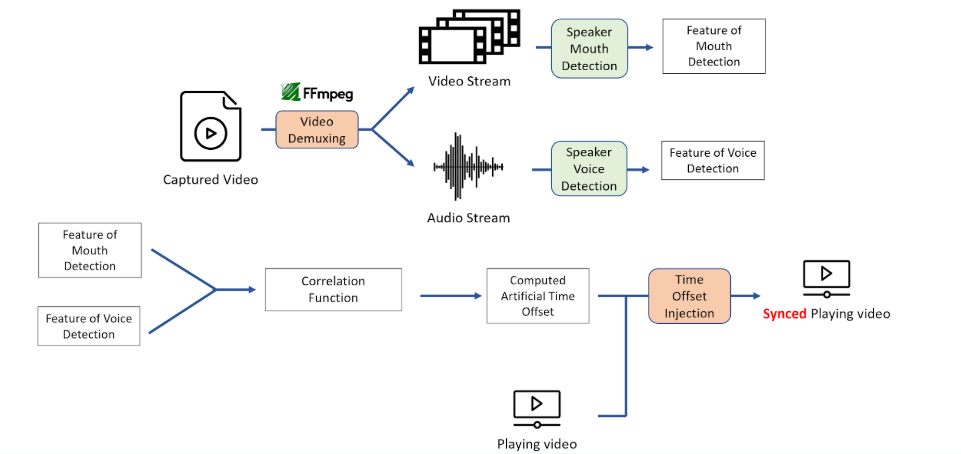
System Block Diagram
Datasets
As it was mentioned before, the scope of this project will be limited to videos that feature a full-frontal view of a single speaker. These videos used in the training and testing datasets were a combination of videos found on the internet, and videos filmed ourselves. By verifying that the implementation works on both types of videos, we are able to show the robustness of our system on different types of full-frontal speaker videos. By using the pydub Python module, silence could be manually inserted at the beginning or the end of the audio file to artifically inject offsets between the video and audio streams. This allows for dozens of datasets to be created from a single base video. FFmpeg was used to separate the original video and audio streams, and to also combine the shifted audio streams with the original video stream to create the data sets. The links to the Google Drive with the data files can be found below:
Training and Optimization of Parameters
The model was trained to optimize two parameters: VAD aggressiveness and MAR threshold. The MAR values were converted to binary based on the threshold for consistency with the binary VAD data. The loss function is the absolute difference between the predicted offset and the actual offset. The optimization routine iterates through all possible VAD aggressiveness values (integers 0 through 3) and utilizes scipy’s optimize.minimize_scalar function to minimize the loss on the MAR threshold. The combination of VAD aggressiveness and MAR threshold that yields the minimum loss is returned. Later, we found that not converting the MARs to binary resulted in a better fit. The model was then optimized again only for the VAD aggressiveness.
This approach can be found under: Strategy 2 on Google Colab