Table of Contents
Experimental Results
Processing the Entire Video File
The following test results come from two base videos. One of them is a clip of a CNN news report, while the other has been recorded by us. A total of 51 sets were created for each base video, corresponding to audio/video offsets of -1s to 1s in increments of 40ms. The following histogram shows the error between the computed offset and the true offset:

Error between Computed Offset and True Offset
The error in the internet video’s synchronization was consistently one frame, while the error in our own video’s synchronization was consistently two frames. The fact that the synchronization process was able to achieve such a low error demonstrates the existence of a strong correlation between a speaker’s mouth aspect ratio and the detected voice activity from the audio stream. However, the consistency of the error reveals some information that we had not previously considered. There is actually a delay between the time when a speaker opens their mouth and when sound actually comes out. This delay seems to depend on the speaker, but it may be possible to compensate for this error by computing an average across multiple videos with different speakers.
A threshold technique was initially used to assign a binary value to the MAR. The binary value for a particular frame would determine whether the speaker’s mouth was open or closed during that time, according to a specific threshold. In the optimization process described above, this threshold value was included in the optimization over the VAD aggressiveness value. However, the conversion from a continuous MAR to a binary MAR resulted in the unnecessary loss of information. The histogram below shows the computed error with a binary MAR, using the same dataset as the results above:
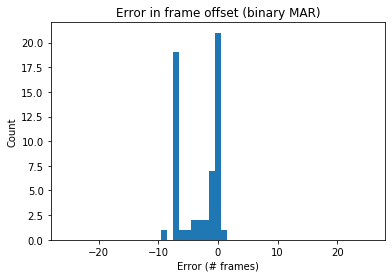
Error using Binary MAR
Using a Variable Window Size
A real-time implementation would not have access to the entire video. In light of this, the model was evaluated on sliding windows of size 1 to 12 seconds rather than whole videos. As before, the maximum offset between any audio-video pair was 25 frames in either direction. Audio-video pairs whose VAD component stayed constant were discarded as no useful information could be gleaned from the audio. As expected, the performance improved with larger window sizes:
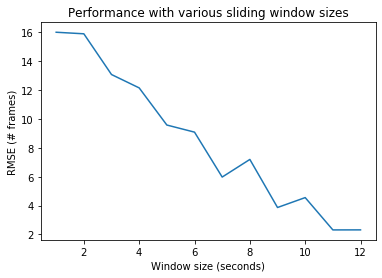
Error using Variable Window Size
Key Findings
- The mouth aspect ratios (MARs) of a speaker in the video has a good correlation to his or her voice activity in the audio.
- Using raw MARs instead of a binary MAR threshold gives better correlation between MAR and voice activity
- There is a consistent offset between when a person opens his or her mouth and when he or she start/resume the talk